


Redshift is a managed data warehousing solution, which can scale to petabytes or more.
Use Redshift to integrate with SQL; Business Intelligence (BI); and Extract, Transform, Load (ETL) tools to generate reports.
Redshift Spectrum allows you to perform SQL queries against exabytes of unstructured data in S3. It scales compute capacity based on the data being retrieved.
Redshift Architecture
A Redshift cluster is a set of nodes that consists of a leader node and one or more compute nodes. The type and number of compute nodes needed depends on the size of the data, the number of queries executed, and the required query execution performance.
Leader node: Receives queries from client applications, parses the queries, and develops execution plans, which are an ordered set of steps to process these queries. The leader node then coordinates the parallel execution of these plans with the compute nodes, aggregates the intermediate results from these nodes, and finally returns the results back to the client applications. You can only have one leader node.
Compute nodes: Execute the steps specified in the execution plans and transmit data among themselves to serve these queries. The intermediate results are sent back to the leader node for aggregation before being sent back to the client applications.
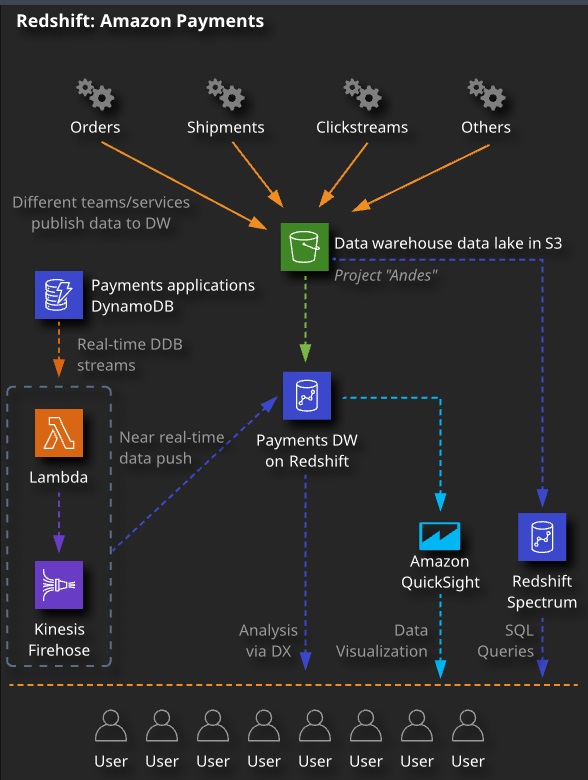
Redshift vs. RDS
Both enable you to run traditional RDBMSs. RDS is typically used for OLTP and reporting. Redshift is appropriate for massively large data sets. Redshift provides excellent scale-out options and can be used to prevent interference with an OLTP workload.
When to use which product?
RDS
- OLTP
- Read replicas across regions
- Snapshots in S3
- Lives inside VPC
- Security is DB user based
Redshift
- OLAP Accessed via SQL
- Massive amounts of data
- Complex queries across multiple data sources
- Lives inside VPC
- Security is DB user based
- Best for structured data (e.g., CSV files)
DynamoDB
- Millisecond read latency
- Fully managed
- No backups required (PITR)
- Security is IAM based
Athena
- Apache Hive Query Language (HQL)
- Single data source
- Queries generally faster than Redshift
- Security is IAM based
- Better for ad hoc querying
Elastic MapReduce (EMR)
- Based on Apache Hadoop
- Best for unstructured data