


DynamoDB is a NoSQL database service. It’s a global service, partitioned regionally and allows the creation of tables.
Key-value databases like DynamoDB are highly partitionable and allow horizontal scaling at scales that other types of databases cannot achieve. Use cases such as web, mobile, gaming, ad tech, and IoT lend themselves particularly well to the key-value data model. DynamoDB is designed to provide consistent single-digit millisecond latency for any scale of workloads.
Partitions and Data Distribution
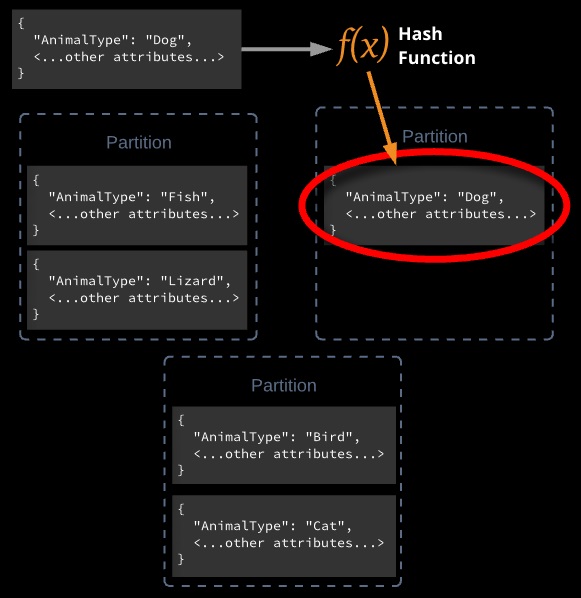
DynamoDB stores data in partitions. A partition is an allocation of storage for a table, backed by solid-state drives (SSDs) and automatically replicated across multiple Availability Zones within an AWS Region.
To get the most out of DynamoDB throughput, create tables where the partition key has a large number of distinct values. Applications should request values fairly uniformly and as randomly as possible.
Tables, Items, Attributes, and Streams
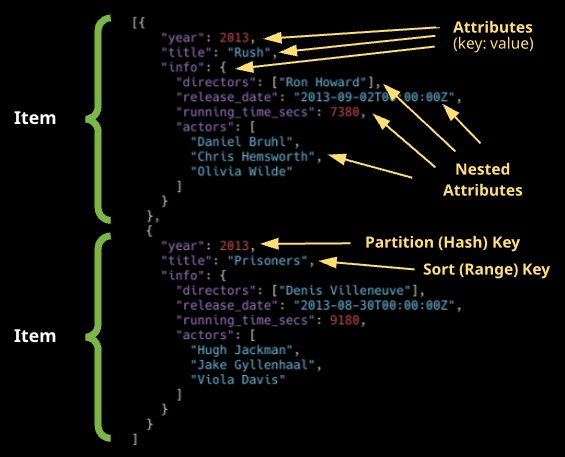
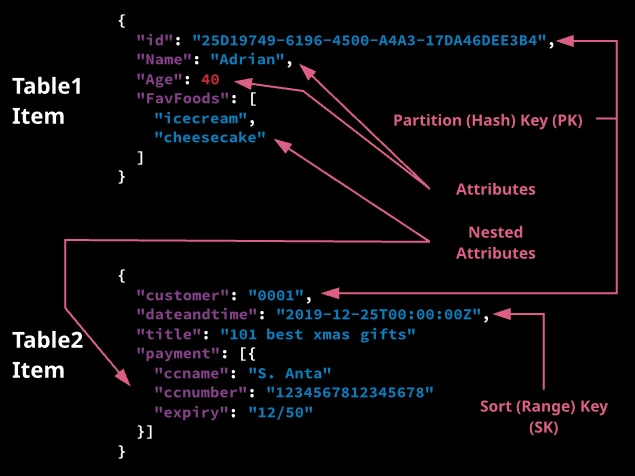
Table: Collection of data. DynamoDB tables must contain a name, primary key, and the required read and write throughput values. Collection of items that share the same partition key (PK) or partition key and sort key (SK) together with other configuration and performance settings.
Item: A table may contain multiple items. An item is a unique group of attributes. Items are similar to rows or records in a traditional relational database. Items are limited to 400 KB. Collection of attributes inside a table that shares the same key structure as every other item in the table.
Attribute: Fundamental data element. Similar to fields or columns in an RDBMS. Key and value – an attribute name and value.
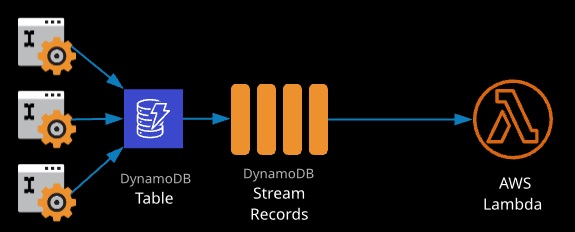
Stream: Ordered flow of information about table changes. For every create, update, or delete of an item, a stream record is created that contains those changes. Streams can be used to copy data from one table to another within a single region.
Streams
When enabled, streams provide an ordered list of changes that occur to items within a DynamoDB table. A stream is a rolling 24-hour window of changes. Streams are enabled per table and only contain data from the point of being enabled.
Every stream has an ARN that identifies it globally across all tables, accounts, and regions.
Streams can be configured with one of four view types:
- KEYS_ONLY: Whenever an item is added, updated, or deleted, the key(s) of that item are added to the stream.
- NEW_IMAGE: The entire item is added to the stream “post-change.”
- OLD IMAGE: The entire item is added to the stream “pre-change.”
- NEW AND OLD IMAGES: Both the new and old versions of the item are added to the stream.
Triggers
Streams can be integrated with AWS Lambda, invoking a function whenever items are changed in a DynamoDB table (a DB trigger).
Data Types
Scalar: Exactly one value — number, string, binary, boolean, and null. Applications must encode binary values in base64-encoded format before sending them to DynamoDB.
Document: Complex structure with nested attributes (e.g.. JSON) — list and map.
Document Types
List: Ordered collection of values
FavoriteThings: [“Cookies”, “Coffee”, 3.14159]
Map: Unordered collection of name-value pairs (similar to JSON)
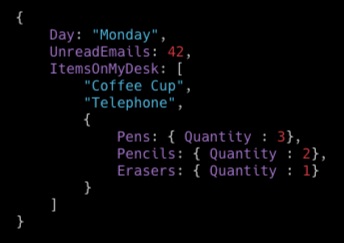
Set: Multiple scalar values of the same type — string set, number set, binary set.
|
1 2 3 |
["Black", "Green", "Red"] [42.2, -19, 7.5, 3.14] ["U3Vubnk=", "UmFpbnk=", "U25vd3k="] |
Read and Write Consistency
DynamoDB replicates data across multiple Availability Zones behind the scenes.
When an application writes data to a DynamoDB table and receives an HTTP 200 response (OK), all copies of the data are updated. The data will eventually be consistent across all storage locations. This is usually within one second or less.
DynamoDB supports eventually consistent and strongly consistent reads.
Eventually Consistent Reads
When you read data from a DynamoDB table, the response might not reflect the results of a recently completed write operation. The response might include some stale data. If you repeat your read request after a short time, the response should return the latest data. DynamoDB uses eventually consistent reads by default.
Strongly Consistent Reads
When you request a strongly consistent read, DynamoDB returns a response with the most up-to-date data, reflecting the updates from all prior write operations that were successful. A strongly consistent read might not be available if there is a network delay or outage.
DynamoDB has two read/write capacity modes:
- provisioned throughput (default)
- on-demand mode.
When using provisioned throughput mode, each table is configured with read capacity units (RCU) and write capacity units (WCU).
Every operation on ITEMS consumes at least 1 RCU or WCU — partial RCU/WCU cannot be consumed.
When using on-demand mode, DynamoDB automatically scales to handle performance demands and bills a per-request charge.
Read Capacity Units
One RCU is 4 KB of data read from a table per second in a strongly consistent way. Reading 2 KB of data consumes 1 RCU, reading 4.5 KB of data takes 2 RCU, reading 10* 400 bytes takes 10 RCU. If eventually consistent reads are okay, 1 RCU can allow for 2 x 4 KB of data reads per second. Atomic transactions require 2x the RCU.
Write Capacity Units
One WCU is 1 KB of data or less written to a table. An operation that writes 200 bytes consumes 1 WCU, an operation that writes 2 KB consumes 2 WCU. Five operations of 200 bytes consumes 5 WCU. Atomic transactions require 2x the WCU to complete.
Provisioned Throughput
Maximum amount of capacity that an application can consume from a table or index. Throttled requests: ProvisionedThroughputExceededException
Read Capacity Units
One read request unit represents one strongly consistent read request per second, or two eventually consistent read requests, for an item up to 4 KB in size. Transactional read requests require 2 read request units for items up to 4 KB.
For an 8 KB item size:
- 2 read request units for one strongly consistent read
- 1 read request unit for an eventually consistent read
- 4 read request units for a transactional read
Write Capacity Units
One write request unit represents one write per second for an item up to 1 KB in size. Transactional write requests require 2 write request units for items up to 1 KB.
For a 2 KB item size:
- 2 write request units
- 4 transactional write request units
On-Demand Mode
DynamoDB instantly accommodates your workloads as they ramp up or down to any previously reached traffic level. This is charged per request.
Reserved Capacity
Pay a one-time upfront fee and commit to a minimum usage level over a period of time, saving money compared to on-demand settings.
Scenario: You create a table with six RCUs and six WCUs. With these settings, your application could do the following:
- Perform strongly consistent reads of up to 24 KB per second (4 KB x 6 read capacity units).
- Perform eventually consistent reads of up to 48 KB per second (twice as much read throughput).
- Perform transactional read requests of up to 12 KB per second.
- Write up to 6 KB per second (1 KB x 6 write capacity units).
- Perform transactional write requests of up to 3 KB per second.
DynamoDB Consistency
DynamoDB is highly resilient and replicates data across multiple AZs in a region. When you receive a HTTP 200 code, a write has been completed and is durable. This doesn’t mean it’s been written to all AZs — this generally occurs within a second.
An eventually consistent read will request data, preferring speed. It’s possible the data received may not reflect a recent write. Eventual consistency is the default for read operations in DDB.
A strongly consistent read ensures DynamoDB returns the most up-to-date copy of data — it takes longer but is sometimes required for applications that require consistency.
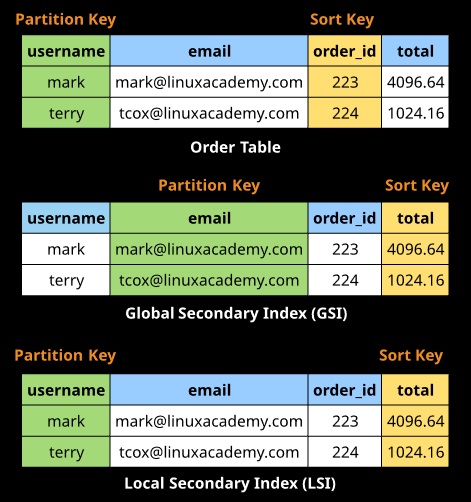
Indexes
Indexes provide an alternative representation of data in a table, which is useful for applications with varying query demands. Indexes come in two forms:
- Local secondary indexes (LSI)
- Global secondary indexes (GSI).
Indexes are interacted with as though they are tables, but they are just an alternate representation of data in an existing table.
Local secondary indexes must be created at the same time as creating a table. They use the same partition key but an alternative sort key. They share the RCU and WCU values for the main table.
Global secondary indexes can be created at any point after the table is created. They can use different partition and sort keys. They have their own RCU and WCU values.
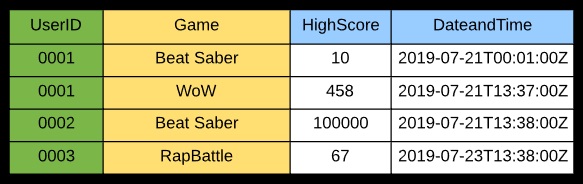
Efficient queries can only be done on user ID and filtered or sorted using game.
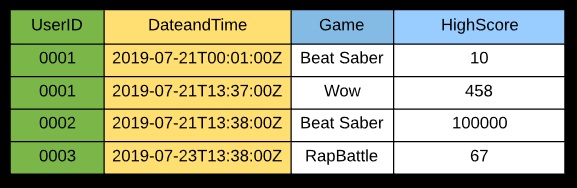
An LSI lets you use an alternative sort key to allow filtering on date and time instead.
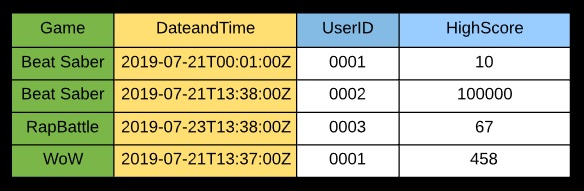
A GSI can use an alternative PK and SK — in this example, maybe for a high score table per game.
Secondary Indexes
Data structure that contains a subset of attributes from a table, along with an alternate key to support query operations. You can retrieve data from the index using a query, just like with a table. A table can have multiple secondary indexes.
Global Secondary Index: Index with a partition key and a sort key that can be different from those on the base table. The primary key of a GSI can be either simple (partition key) or composite (partition key and sort key).
Local Secondaryindex: Index that has the same partition key as the base table, but a different sort key. The primary key of a LSI must be composite (partition and sort key).
On-Demand Backup and Restore
Create full backups of your tables at any time in either the AWS Management Console or with a single API call.
- Backup and restore actions execute with zero impact on table performance or availability.
- Backups are consistent within seconds and retained until deleted.
- Backup and restore operates within the same region as the source table.
Point-in-Time Recovery
Helps protect your DynamoDB tables from accidental writes or deletes. You can restore your data to any point in time in the last 35 days.
- DynamoDB maintains incremental backups of your data.
- Point-in-time recovery is not enabled by default.
- The latest restorable timestamp is typically five minutes in the past.
After restoring a table, you must manually set up the following on the restored table:
- Auto scaling policies
- AWS Identity and Access Management (IAM) policies
- Amazon CloudWatch metrics and alarms
- Tags
- Stream settings
- Time to Live (TTL) settings
- Point-in-time recovery settings
VPC Endpoints
Use VPC endpoints to configure network traffic to be limited to the AWS cloud and avoid using the public internet.
- No need for an internet gateway or NAT gateway (keeps VPCs isolated from the public internet).
- No need to create and maintain firewalls to secure the VPC.
- Restrict access to DynamoDB through VPC endpoints using IAM policies.
VPC Endpoint Policy
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
{ version": "2012-10-17", "Statement": [ { "Sid": "AccessFromSpecificEndpoint", "Action": "dynamodb:*", "Effect": "Deny", "Resource": "arn:aws:dynamodb: region: 123456789012:mytable/*", "Condition": { "StringNotEquals": { "aws:sourceVoce": "vpce-llaa22bb33cc" } } } ] } |
When Not to Use DynamoDB
Before deciding to use DynamoDB, you should be able to answer “yes” to most of the following evaluation questions:
- Can you organize your data in hierarchies or a structure in one or two tables?
- Are data encryption and protection important?
- Are traditional backups impractical or cost-prohibitive because of table update rate or overall data size?
- Does your database workload vary significantly by time of day, or is it driven by a high growth rate or high-traffic events?
- Does your application or service consistently require response time in single milliseconds, regardless of loading and without tuning effort?
- Do you need to provide services in a scalable, replicated, or global configuration?
- Does your application need to store data in the high-terabyte size range?
- Are you willing to invest in a short but possibly steep NoSQL learning curve for your developers?
Some unsuitable workloads for DynamoDB include:
- Services that require ad hoc query access.
- Online analytical processing (OLAP), business intelligence (BI), or data warehouse implementations. Consider Amazon Redshift instead.
- Binary large object (BLOB) storage. DynamoDB can store binary items up to 400 KB, but DynamoDB is not generally suited to storing documents or images. The best architectural practice here is to store pointers to Amazon S3 objects in a DynamoDB table.