Aurora is a database engine developed by AWS that is compatible with MySQL, PostgreSQL and associated tools. Fully managed, highly available, relational database engine.
Features
- MySQL and PostgreSQL compatible
- Up to 5x faster than MySQL and 3x faster than PostgreSQL without changing your applications
- Fully managed, performing routine tasks:
- Provisioning
- Patching
- Backup and recovery
- Failure detection and repair
- Migration tools to convert RDS MySQL databases to Aurora
- Greater than 99.99% availability
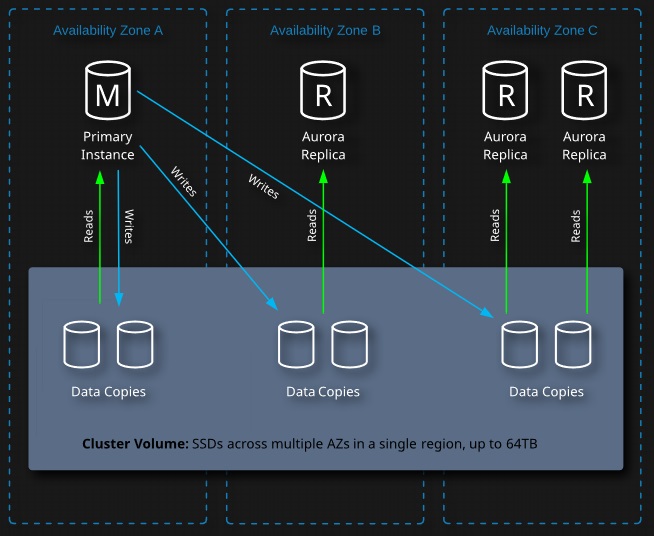
Aurora operates with a radically different architecture as opposed to the other RDS database engines:
- Aurora uses a base configuration of a “cluster”
- A cluster contains a single primary instance and zero or more replicas
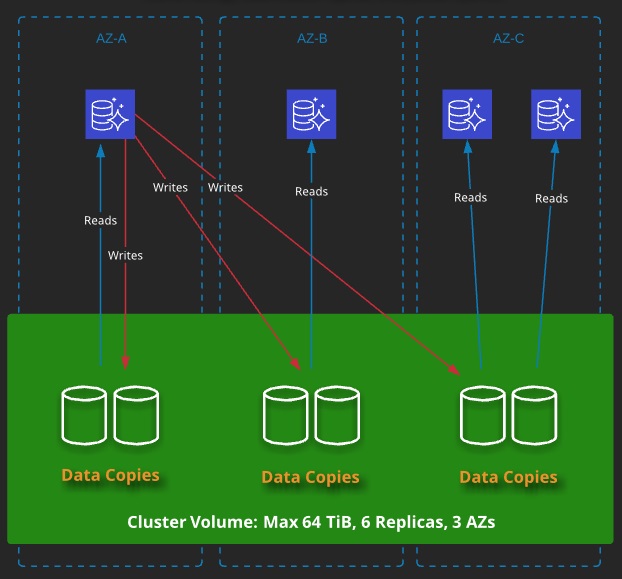
Cluster Storage
All instances (primary and replicas) use the same shared storage — the cluster volumes.
- Cluster volume is totally SSD based, which can scale to 64 TiB in size.
- Replicates data six times, across three Availability Zones.
- Aurora can tolerate two failures without writes being impacted and three failures without impacting reads.
- Aurora storage is auto-healing.
Cluster Scaling and Availability
- Cluster volume scales automatically, only bills for consumed data, and is constantly backed up to S3.
- Aurora replicas improve availability, can be promoted to be a primary instance quickly, and allow for efficient read scaling.
- Reads and writes use the cluster endpoint.
- Reads can use the reader endpoint, which balances connections over all replica instances.
Aurora is not just an enhancement of RDS — it’s a new architecture with
- shared storage,
- addressable replicas
- parallel queries.
To improve resilience, use additional replicas. To scale write workloads, scale up the instance size. To scale reads, scale out (adding more replicas).
Aurora Architecture
Distributed, fault-tolerant, self-healing storage system that scales up to 64 TB per DB instance.
- Scales in 10 GB increments
- Replicates six copies of your data across three AZs
- Single virtual volume using SSDs
- Lose two copies of data without affecting writes
- Lose three copies of data without affecting reads
- Continuously backs up to S3
- Restore from a DB snapshot or use point-in-time restore (PITR)
- Global Database can span multiple regions
- Parallel Query for MySQL distributes I/O across the storage layer for performa nce
- Security using IAM Database Authentication and VPC Security Groups
- Encrypt data at rest (on by default) with KMS or in transit with SSL
- Read replicas (encrypted if primary is)
- Increase performance
- Failover targets (can be promoted to primary)
Scenario: Aurora is near 100% CPU utilization. If writes then scale up (increase instance size). If reads then scale out (increase number of replicas).
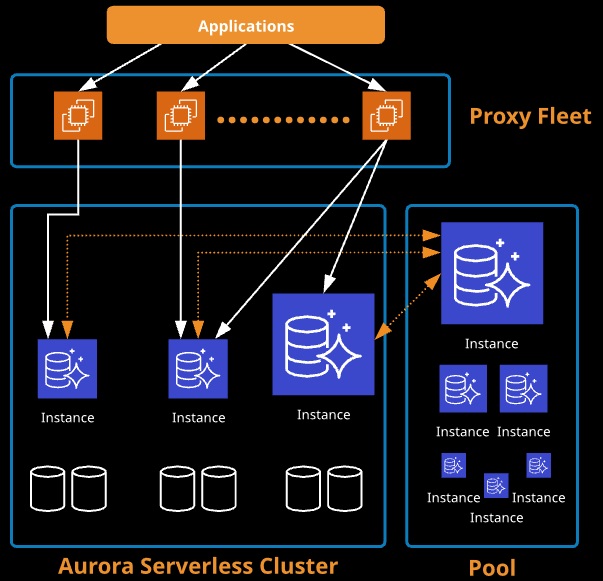
Aurora Serverless
Aurora Serverless is based on the same database engine as Aurora, but instead of provisioning certain resource allocation, Aurora Serverless handles this as a service. You simply specify a minimum and maximum number of Aurora capacity units (ACUs) — Aurora Serverless can use the Data API.
On-demand auto-scaling configuration for Aurora. No instances to manage. Charged on a per-second basis.