


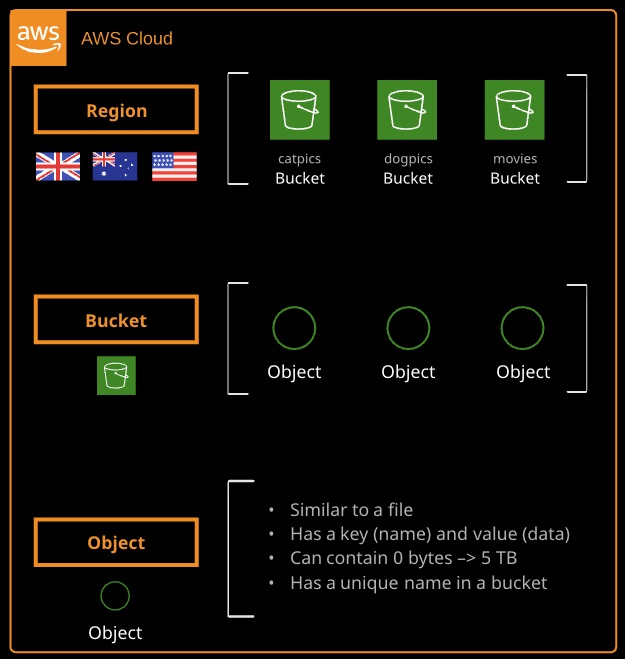
Simple Storage Service (S3) is a global object storage platform that can be used to store objects in the form of text files, photos, audio, movies, large binaries, or other object types.
S3 Fundamentals
- Bucket names have to be globally unique
- Minimum of 3 and maximum of 63 characters — no uppercase or underscores
- Must start with a lowercase letter or number and can’t be formatted as an IP address (1.1.1.1)
- Default 100 buckets per account, and hard 1000-bucket limit via support request
- Unlimited objects in buckets
- Unlimited total capacity for a bucket
- An object’s key is its name
- An object’s value is its data
- An object’s size is from 0 to 5 TB
Every object stored in S3 has an associated storage class — also called a storage tier. Storage classes can be adjusted either manually or automatically using lifecycle policies. All storage classes have 99.999999999% (11 nines) durability.
Storage classes determine the cost of storage, the availability, durability, and latency for object retrieval.
The current classes for S3 object storage are:
Standard
- Designed for general, all-purpose storage
- The default storage option
- Designed for 99.99% (four nines) availability
- 3+ AZ replication
- Most expensive storage class, but has no minimum object size and no retrieval fee
Intelligent-Tiering
- Moves objects across access tiers based on usage patterns
- Same performance as Standard
Standard Infrequent Access (Standard-IA)
- Designed for important objects, where access is infrequent, but rapid retrieval is a requirement
- Designed for 99.9% (three nines) availability
- 3+ AZ replication
- Cheaper than the Standard storage class
- 30-day minimum storage charge per object, 128 KB minimum storage charge, object retrieval fee
One Zone-IA
- Designed for non-critical, reproducible objects
- Designed fo 99.5% availability
- 1 AZ replication (less resilient)
- Cheaper than the Standard or Standard-IA storage classes
- 30-day minimum storage charge per object, 128 KB minimum storage charge, object retrieval fee
Glacier
- Designed for long-term archival storage (not to be used for hot backups)
- May take several minutes or hours for objects to be retrieved (several options available)
- Designed for 99.99% (four nines) availability
- 3+ AZ replication
- 90-day minimum charge per object,
- 40 KB minimum storage charge, object retrieval fee
Glacier Deep Archive
- Designed for long-term archival storage Ideal alternative to tape backups Cheaper than normal Glacier, but retrievals take longer
- Designed for 99.99% (four nines) availability
- 3+ AZ replication May take several hours for objects to be retrieved
- 180-day minimum charge per object,
- 40 KB minimum storage charge, object retrieval fee
Glacier Terminology
Archive
- A durably stored block of information
- TAR and ZIP are common formats used to aggregate files
- Total volume of data and number of archives is unlimited
- Each archive can be up to 40 TB
- Largest single upload is 4 GB (use multipart upload >100 MB)
- Archives can be uploaded and deleted, but not edited or overwritten
Vault
- A way to group archives together
- Control access using vault-level access policies using IAM
- SNS notifications available for when retrieval requests are ready for download
Vault Lock
- Lockable policy to enforce compliance controls on vaults
- Vault lock policies are immutable
Lifecycle rules
Storage classes can be controlled via lifecycle rules, which allow for the automated transition of objects between storage classes, or in certain cases allow for the expiration of objects that are no longer required. Rules are added at a bucket level and can be enabled or disabled based on business requirements.
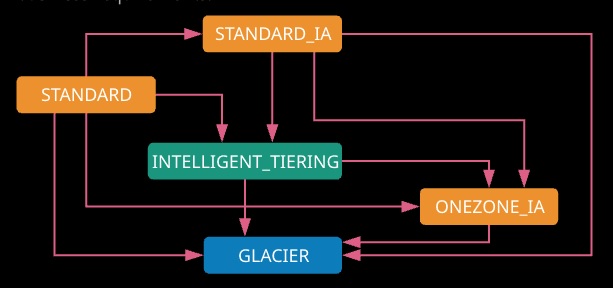
Objects smaller than 128 KB cannot be transitioned into INTELLIGENT TIERING. Objects must be in the original storage class for a minimum of 30 days before transitioning them to either of the IA storage tiers. Instead of transitioning between tiers, objects can be configured to expire after certain time periods. At the point of expiry, they are deleted from the bucket.
Objects can be archived into Glacier using lifecycle configurations. The objects remain inside S3, managed from S3, but Glacier is used for storage. Objects can be restored into S3 for temporary periods of time —after which, they are deleted. If objects are encrypted, they remain encrypted during their transition to Glacier or temporary restoration into S3.
Bucket authorization within S3 is controlled using identity policies on AWS identities, as well as bucket policies in the form of resource policies on the bucket and bucket or object ACLs.
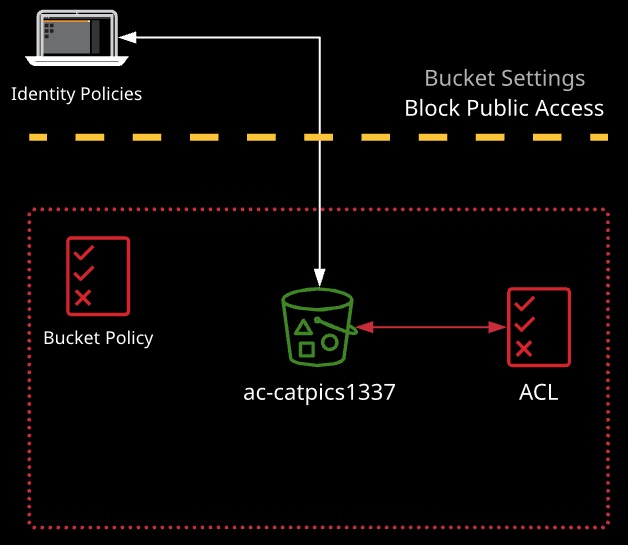
Final authorization is a combination of all applicable policies. Priority order is (1) Explicit Deny, (2) Explicit Allow, (3) Implicit Deny.
Uploads to S3 are generally done using the S3 console, the CLI, or directly using the APIs. Uploads either use a single operation (known as a single PUT upload) or multipart upload.

Limit of 5 GB, can cause performance issues, and if the upload fails the whole upload fails

An object is broken up into parts (up to 10,000), each part is 5 MB to 5 GB, and the last part can be less (the remaining data)
Multipart upload is faster (parallel uploads), and the individual parts can fail and be retried individually. AWS recommends multipart for anything over 100 MB, but it’s required for anything beyond 5 GB.
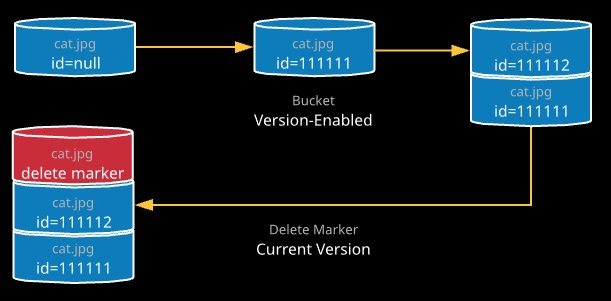
Versioning
Versioning can be enabled on an S3 bucket. Once enabled, any operations that would otherwise modify objects generate new versions of that original object. Once a bucket is version-enabled, it can never be fully switched off — only suspended.
With versioning enabled, an AWS account is billed for all versions of all objects. Object deletions by default don’t delete an object — instead, a delete marker is added to indicate the object is deleted (this can be undone). Older versions of an object can be accessed using the object name and a version ID. Specific versions can be deleted.
MFA Delete is a feature designed to prevent accidental deletion of objects. Once enabled, a one-time password is required to delete an object version or when changing the versioning state of a bucket.
S3 cross-region replication (S3 CRR) is a feature that can be enabled on S3 buckets allowing one-way replication of data from a source bucket to a destination bucket in another region.
By default, replicated objects keep their:
- Storage class
- Object name (key)
- Owner
- Object permissions
Replication configuration is applied to the source bucket, and to do so requires versioning to be enabled on both buckets. Replication requires an IAM role with permissions to replicate objects. With the replication configuration, it is possible to override the storage class and object permissions as they are written to the destination.
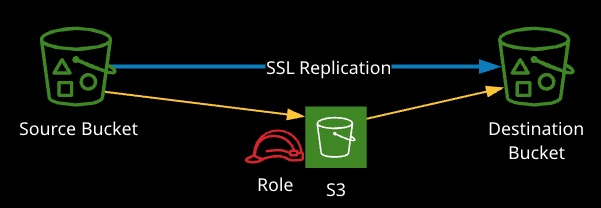
Excluded from Replication
- System actions (lifecycle events)
- Any existing objects from before replication is enabled
- SSE-C encrypted objects — only SSE-S3 and (if enabled) KMS encrypted objects are supported
Hosting websites
Amazon S3 buckets can be configured to host websites. Content can be uploaded to the bucket and when enabled, static web hosting will provide a unique endpoint URL that can be accessed by any web browser. S3 buckets can host many types of content, including:
- HTML, CSS, JavaScript
- Media (audio, movies, images)
S3 can be used to host front-end code for serverless applications or an offload location for static content. CloudFront can also be added to improve the speed and efficiency of content delivery for global users or to add SSL for custom domains.
Route 53 and alias records can also be used to add human-friendly names to buckets.
Cross-Origin Resource Sharing (CORS)
CORS is a security measure allowing a web application running in one domain to reference resources in another.

AWS Storage Gateway
Connects local data center software appliances to cloud-based storage, such as Amazon S3. We can use it for hybrid cloud backup, archiving and disaster recovery, tiered storage, application file storage, and data processing workflows.
File Gateway
- Comprises the S3 service and a virtual appliance
- Allows for storage and retrieval of files in S3 using standard file protocols (NFS and SMB)
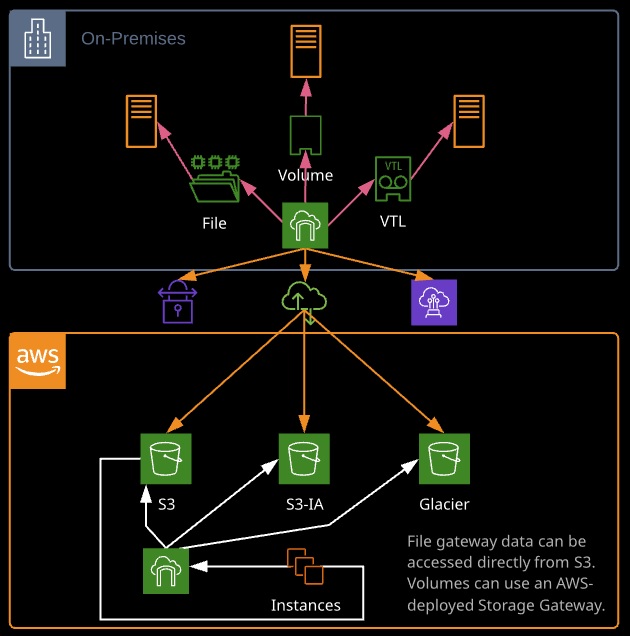
Volume Gateway
– Gateway-Cached Volumes
- Create storage volumes and mount them as iSCSI devices on the on-premises servers
- The gateway will store the data written to this volume in Amazon S3 and will cache frequently accessed data on-premises in the storage device
– Gateway-Stored Volumes
- Store all the data locally (on-premises) in storage volumes
- Gateway will periodically take snapshots of the data as incremental backups and store them on Amazon S3
Tape Gateway
- A cloud virtual tape library that writes to Glacier
- Used for archiving data
- Can run as a VM on-premises or on an EC2 instance
Encryption
Data between a client and S3 is encrypted in transit. Encryption at rest can be configured on a per-object basis.
- Client-Side Encryption: The client/application is responsible for managing both the encryption/decryption process and its keys. This method is generally only used when strict security compliance is required — it has significant admin and processing overhead.
- Server-Side Encryption with Customer-Managed Keys (SSE-C): S3 handles the encryption and decryption process. The customer is still responsible for key management, and keys must be supplied with each PUT or GET request.
- Server-Side Encryption with S3-Managed Keys (SSE-S3): Objects are encrypted using AES-256 by S3. The keys are generated by S3 (using KMS on your behalf). Keys are stored with objects in an encrypted form. If you have permissions on the object (e.g., S3 Read or S3 Admin), you can decrypt and access it.
- Server-Side Encryption with AWS KMS-Managed Keys (SSE-KMS): Objects are encrypted using individual keys generated by KMS. Encrypted keys are stored with the encrypted objects. Decryption of an object needs both S3 and KMS key permissions (role separation).
Bucket Default Encryption
Objects are encrypted in S3, not buckets. Each PUT operation needs to specify encryption (and type) or not. A bucket default captures any PUT operations where no encryption method/directive is specified. It doesn’t enforce what type can and can’t be used. Bucket policies can enforce.
A presigned URL can be created by an identity in AWS, providing access to an object using the creator’s access permissions. When the presigned URL is used, AWS verifies the creator’s access to the object — not yours. The URL is encoded with authentication built in and has an expiry time.
Presigned URLs can be used to download or upload objects.
Any identity can create a presigned URL — even if that identity doesn’t have access to the object.
Example presigned URL scenarios:
- Stock images website — media stored privately on S3, presigned URL generated when an image is purchased
- Client access to upload an image for process to an S3 bucket
When using presigned URLs, you may get an error. Some common situations include:
- The presigned URL has expired — seven-day maximum
- The permissions of the creator of the URL have changed
- The URL was created using a role (36-hour max) and the role’s temporary credentials have expired (aim to never create presigned URLs using roles)