AMI Virtualization Types
Hardware Virtual Machine (HVM) AMIs
- Executes the master boot record of the root storage device
- Virtual hardware set allows for running an OS as if it were run on bare metal; the OS doesn’t know it’s virtualized
- No modification needed
- Can use hardware extensions Provides fast access to host hardware Enhanced networking and GPU processing
Paravirtual (PV) AMIs
- Runs a special boot loader and then loads the kernel
- Can run on hardware that does not support virtualization
- No hardware extension support
- PV historically performed faster than HVM, but that is no longer the case
- PV has special drivers for networking and storage that used less overhead than an HVM instance trying to emulate the hardware. These drivers can now be run on HVM instances, making the performance of both types the same.
NOTE: AWS now recommends using HVM instances because the performance is the same as PV, and enhanced networking and GPU processing can be utilized when necessary.
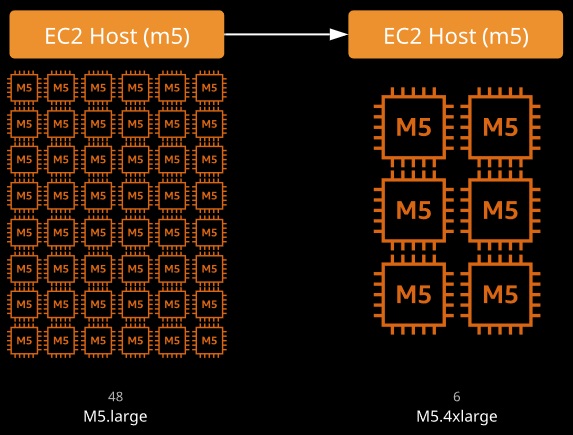
EC2 instances are grouped into families, which are designed for a specific broad type workload. The type determines a certain set of features, and sizes decide the level of workload they can cope with.
The current EC2 families:
- General Purpose,
- Compute Optimized,
- Memory Optimized,
- Storage Optimized,
- Accelerated Computing.
Instance types include:
- T2 and T3: Low-cost instance types that provide burst capability
- M5: For general workloads
- C4: Provides more capable CPU
- X1 and R4: Optimize large amounts of fast memory
- I3: Delivers fast IO
- P2, G3, and Fl: Deliver GPU and FPGAs
Instance sizes include nano, micro, small, medium, large, x.large, 2x.large, and larger.
Special Cases
- “a”: Use AMD CPUs
- “A”: Arm based
- “n”: Higher speed networking
- “d”: NVMe storage
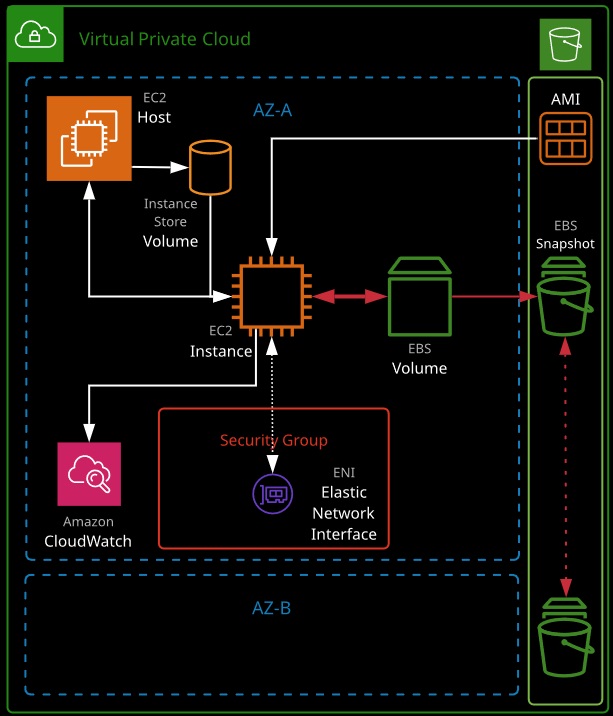
Instance Metadata
Instance metadata is data relating to the instance that can be accessed from within the instance itself using a utility capable of accessing HTTP and using the URL:
http://169.254.169.254/latestimeta-data
AMI used to create the instance:
http://169.254.169.254/latest/meta-data/ami-id
Instance ID:
http://169.254.169.254/latest/meta-data/instance-id
Instance type:
http://169.254.169.254/latest/meta-data/instance-type
Instance metadata is a way that scripts and applications running on EC2 can get visibility of data they would normally need API calls for.
The metadata can provide the current external IPv4 address for the instance, which isn’t configured on the instance itself but provided by the Internet gateway in the VPC. It provides the Availability Zone the instance was launched in and the security groups applied to the instance. In the case of spot instances, it also provides the approximate time the instance will terminate.
For the exam: Remember the IP address to access metadata.
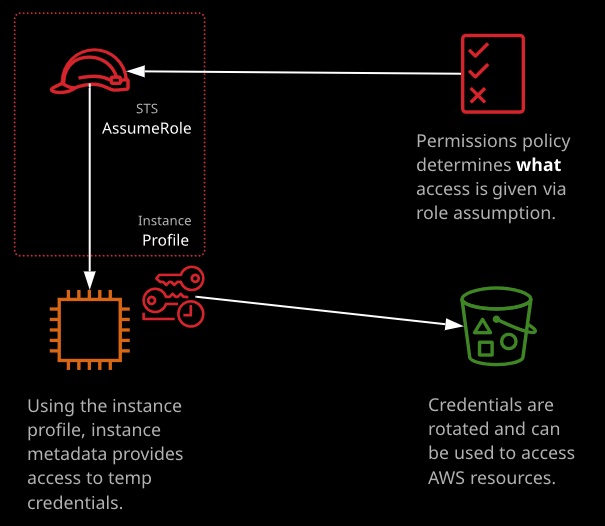
EC2 instance roles are IAM roles that can be “assumed” by EC2 using an intermediary called an instance profile. An instance profile is either created automatically when using the console UI or manually when using the CLI. It’s a container for the role that is associated with an EC2 instance.
The instance profile allows applications on the EC2 instance to access the credentials from the role using the instance metadata.
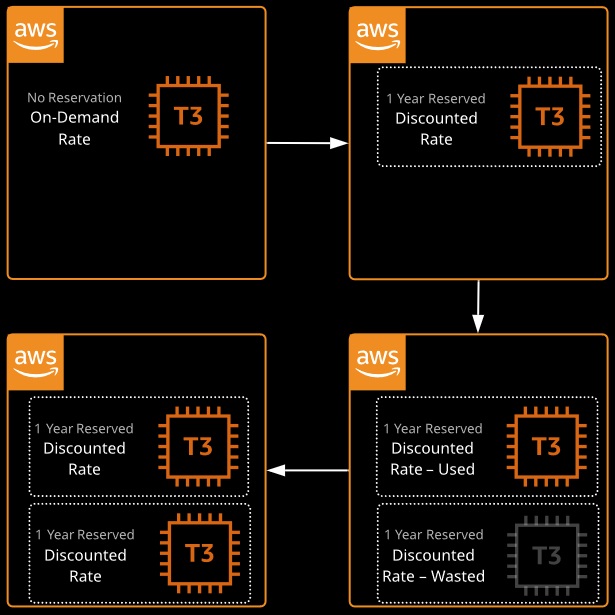
Reserved Instances
Reserved instances lock in a reduced rate for one or three years. Zonal reserved instances include a capacity reservation. Your commitment incurs costs even if instances aren’t launched. Reserved purchases are used for long-running, understood, and consistent workloads.
- Reserved Instances give us the ability to purchase instance capacity for a specific period of time (12 or 36 months).
- We can choose Standard Reserved Instances or Scheduled Reserved Instances. Offer discounts Reserve capacity
Reserved Instance Marketplace
- If requirements or needs change, we can sell Reserved Instances in the marketplace.
- Sellers can avoid wasting capacity and money.
- Buyers can get shorter terms.
Amazon RDS and ElastiCache
- Reserved capacity is also available for Amazon RDS instances and ElastiCache nodes.
- New generations of Reserved Cache Nodes only offer Heavy Utilization nodes, while older generations offer Heavy, Medium, and Light Utilization.
Reserved Instance Scenarios
Scenario 1: A company is using large T2 instances but is expecting consistent growth and needs to upgrade to M4 instances towards the end of the year. M4 instances will put the company over budget, but they know that they’ll be able to use that instance type for at least 3 years. What can they do?
Solution: They could purchase Reserved Instances.
Explanation: Reserved M4 instances purchased under a 3-year term could offer significant discounts. Even if the company needs to change instance sizes, as long as they are still M4 instances running non-licensed Linux platforms, they can change their Reserved Instances at no extra cost.
Scenario 2: We work for an e-commerce platform that loses $X per minute of downtime. We set up Auto Scaling for elasticity. One day, during our peak hour of sales, AWS returns the following error when Auto Scaling attempts to launch more instances: “InsufficientInstanceCapacity”. This causes our instances to be overworked and miss requests. As a result, we lose a lot of sales. How can we avoid this in the future?
Solution: We could purchase Reserved Instances.
Explanation: When we purchase Reserved Instances, we’re purchasing capacity. Even if we don’t need it 100% of the time, it’s there if we need it. That means we don’t have to rely on AWS having enough On-Demand capacity. We could also purchase Scheduled Reserved Instances for peak hours.
Spot instances allow consumption of spare AWS capacity for a given instance type and size in a specific AZ. Instances are provided for as long as your bid price is above the spot price, and you only ever pay the spot price. If your bid is exceeded, instances are terminated with a two-minute warning.
Spot fleets are a container for “capacity needs.” You can specify pools of instances of certain types/sizes aiming for a given “capacity.” A minimum percentage of on-demand can be set to ensure the fleet is always active.
Spot instances are perfect for non-critical workloads, burst workloads, or consistent non-critical jobs that can tolerate interruptions without impacting functionality.
Dedicated hosts are EC2 hosts for a given type and size that can be dedicated to you. The number of instances that can run on the host is fixed — depending on the type and size.
An on-demand or reserved fee is charged for the dedicated host — there are no charges for instances running on the host. Dedicated hosts are generally used when software is licensed per core/CPU and not compatible with running within a shared cloud environment.
EC2: Initializing Volumes
- New EBS volumes operate at maximum performance as soon as they are available.
- For volumes restored from snapshots:
– Maximum performance is not reached until all the blocks on the volume are read.
– Must be initialized (reading all the blocks).
- Some utilities we can use: Isblk, dd, fio
|
1 |
sudo dd if=/dev/xvdf of=/dev/null bs=1M |
|
1 |
sudo fio --filename=/dev/xvdf \ --rw=read \ --bs=128k \ --iodepth=32 \ --ioengine=libaio \ --direct=1 \ --name=volume-initialize |
System Status Checks
• Monitor the systems on which your instances run
Reasons for failure:
- Loss of network connectivity
- Loss of system power
- Software issues on physical host
- Hardware issues on the physical host that impact network reachability
- Even though AWS will have to correct the original issue, we can resolve it ourselves
• For EBS-backed instances: Stop and start instance to obtain new hardware
• For instance store-backed instances: Terminate and replace (can’t stop) the instance for new hardware. Can’t recover data
Instance Status Checks
• Monitor the network and software configuration on an instance
• You must intervene to fix
Reasons for failure:
- Failed system status checks
- Incorrect networking or startup configuration e Exhausted memory
- Corrupted file system e Incompatible kernel Solutions:
- Make instance configuration changes Reboot the instance
Viewing Status Checks Using the AWS CLI
|
1 |
aws ec2 describe-instance-status [--instance-ids 1-1234567890] |
Show instances with impaireds status:
|
1 |
aws ec2 describe-instance-status --filters Name=instance-status.status,Values=impaired |
Auto Scaling
- Distributes the load across multiple instances
- Uses metrics and rules to automate spinning up/terminating instances
- Auto Scaling can scale or shrink on a schedule:
– One-time occurrence or recurring schedule
– Can define a new minimum, maximum, and scaling size
– Lets you scale out before you actually need capacity in order to avoid delays
Changing Instance Sizes
• Increases/decreases resources available to our application
When to choose one over the other? … They both have pros and cons.
Challenges of Auto Scaling
- Auto Scaling is relatively complicated to set up:
– Instances can be started and stopped at any time
– Applications need to be designed to handle distributed work
– Important data (sessions, images, etc.) needs to be stored in a central location
– If one server terminates, the application should still function
- Delays in scaling:
– Instances take time to initialize
– Applications may require setup, which could take even more time
Challenges of Resizing Instances
- Compatibility: Instances must have the same virtualization type to resize
- EBS-backed instances need to be stopped before resizing
- Instance store-backed instances require migration
- Resizing isn’t very flexible compared to Auto Scaling
- There usually has to be downtime and careful planning
- Resizing instances in Auto Scaling groups may need “suspending”.
Auto Scaling vs. Resizing Instances
Scenario 1: Our PHP application is growing in terms oI demand and needs to be highly available. It should scale with demand and shrink back down during slower times. It should also be able to withstand an Availability Zone going down. For these reasons, we’ve implemented Auto Scaling.
Should we also resize instances?
- We may not want to launch a lot of smaller instances if we can launch fewer larger ones.
- We could launch specialized instances to meet the needs of our application if we need more of one type of resource (compute optimized, for example).
Scenario 2: We have an application that processes customer orders with the help of SQS. Orders are added to a queue, which is then polled by backend instances that process the orders. To meet capacity, we launch a certain number of instances. The issue is that sales change depending on the season, time of day, and day of the week.
Should we Auto Scale, resize instances, or both?
- Upgraing instance sizes to meet peaks in sales would leave us overpaying during slow periods.
- We can use Auto Scaling to check the queue length and adjust based off of that.
- Auto Scaling makes the most sense in this scenario.
Common Issues:
- Attempting to use the wrong subnet
- Availability zone is no longer available or supported
- Security group does not exist
- Key pair associated does not exist
- Auto Scaling configuration is not working correctly
- Instance type specification is not supported in that Availability Zone
- Auto Scaling service is not enabled on the account
- Invalid EBS device mapping
- Attempting to attach EBS block device to an instance store AMI
- AMI issues
- Placement group attempting to use the wrong instance type
- “We currently do not have sufficient instance capacity in the AZ that you requested”
- Updating instance in Auto Scaling group with “suspended state”
EC2 Encryption
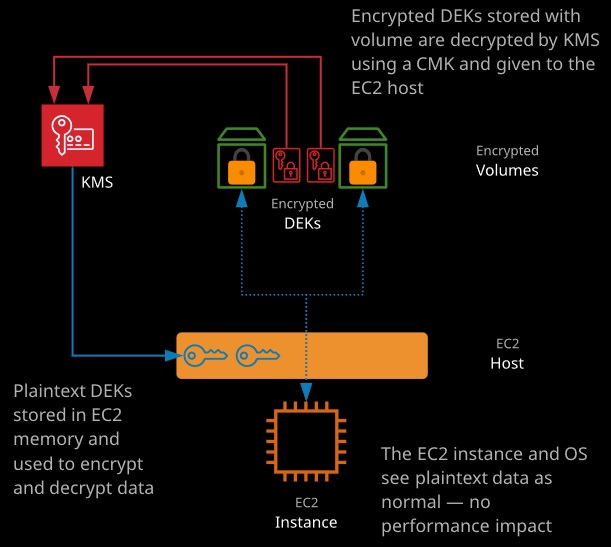
Volume encryption uses EC2 host hardware to encrypt data at rest and in transit between EBS and EC2 instances. Encryption generates a data encryption key (DEK) from a customer master key (CMK) in each region. A unique DEK encrypts each volume. Snapshots of that volume are encrypted with the same DEK, as are any volumes created from that snapshot.
Traditionally, virtual networking meant a virtual host (EC2 host) arranging access for n virtual machines to access one physical network card — this multitasking is done in software and is typically slow.
Enhanced networking uses SR-IOV, which allows a single physical network card to appear as multiple physical devices. Each instance can be given one of these (fake) physical devices. This results in faster transfer rates, lower CPU usage, and lower consistent latency. EC2 delivers this via the Elastic Network Adapter (ENA) or Intel 82599 Virtual Function (VF) interface.
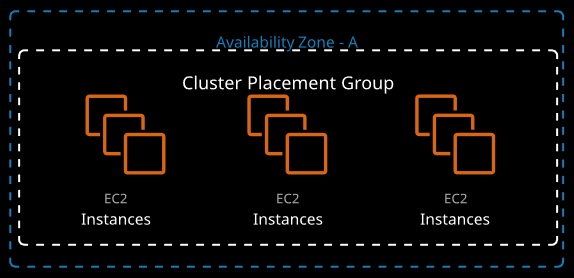
Cluster placement groups place instances physically near each other in a single AZ. Every instance can talk to every other instance at the same time at full speed. Works with enhanced networking for peak performance.
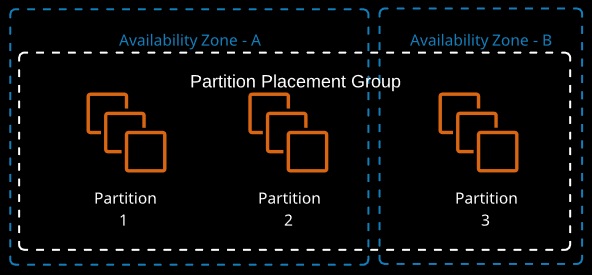
Instances deployed into a partition placement group (PPG) are separated into partitions (max of seven per AZ), each occupying isolated racks in AZs/regions. PPG can span multiple AZs in a region. PPGs minimize failure to a partition and give you visibility on placement.
Spread placement groups (SPGs) are designed for a max of seven instances per AZ that need to be separated. Each instance occupies a partition and has an isolated fault domain. Great for email servers, domain controllers, file servers, and application HA pairs.