


Amazon Elastic MapReduce (EMR) is a tool for large-scale parallel processing of big data and other large data workloads. It’s based on the Apache Hadoop framework and is delivered as a managed cluster using EC2 instances. EMR is used for huge-scale log analysis, indexing, machine learning, financial analysis, simulations, bioinformatics, and many other large-scale applications.
The master node manages the cluster. It manages HDFS naming, distributes workloads, and monitors health. You log in to the master node via SSH. If the master node fails, the cluster fails.
Data can be input from and output to S3. Intermediate data can be stored using HDFS in the cluster or EMRFS using S3.
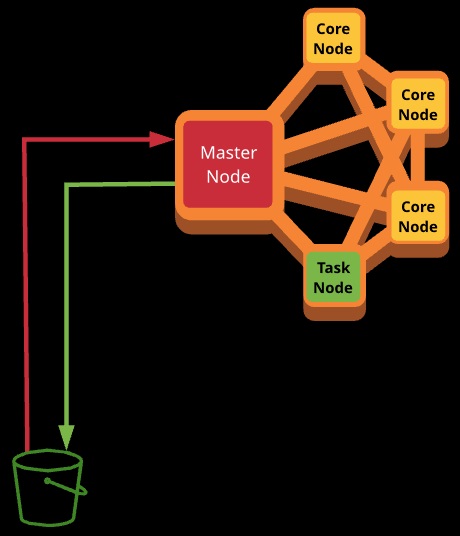
EMR clusters have zero or more core nodes, which are managed by the master node. They run tasks and manage data for HDFS. If they fail, it can cause cluster instability.
Task nodes are optional. They can be used to execute tasks, but they have no involvement with important cluster functions, which means they can be used with spot instances. If task nodes fail, a core node starts the task on another task/core node.